
「午後問題のデータベースがなかなか解けない!」
「SQL文ってよくわかんない・・・」
そんな方の悩みを抱えている方は、ぜひこの記事を読んでみてください!
この記事はこんな人向けです!
本記事は、「そもそもSQLって何?」ということはわかっている前提で話を進めていきますので、超超基礎的な部分に関しては参考書、テキストを買って勉強してみることをおすすめします。
もしくは応用情報技術者試験の1つ下のレベルである、「基本情報技術者試験(FE)」の勉強をしてみるのも良いでしょう。
データ操作言語の基礎知識① 集合演算
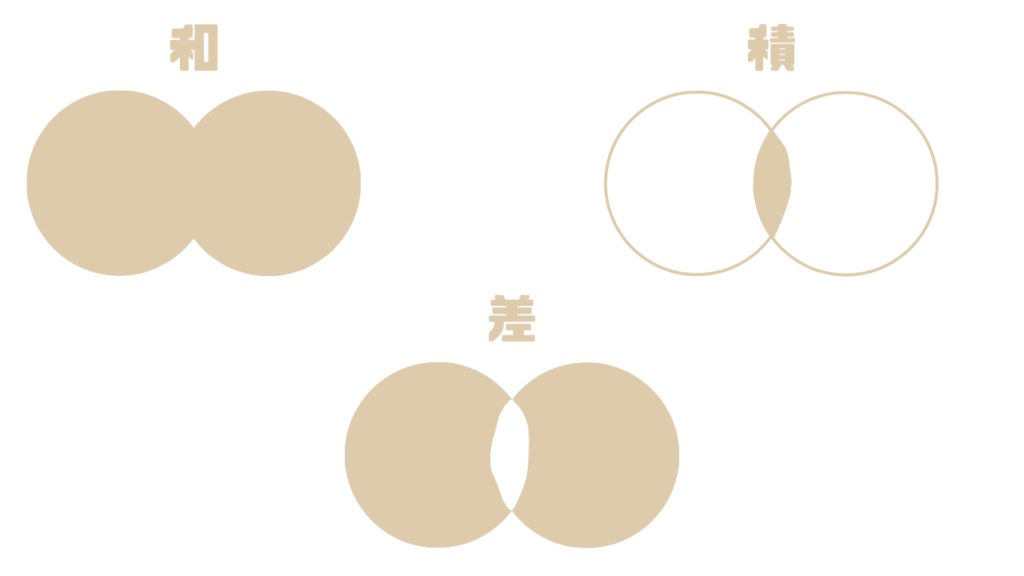
集合演算とは、2つの表を用いて新しい表を作るための演算です。
論理演算(AND、OR、NOT)とよく似ているので、論理演算さえわかっていればすぐにマスターできると思います。
UNION
UNIONは論理演算で言う「和(OR)」です。
SELECT 列名または* FROM 表1UNION SELECT 列名または* FROM 表2
これで、表1と表2を合わせた表を作成できます。例えば、「1組の出席簿と2組の出席簿をくっつける」ような感じで、同じ形の表同士を縦にくっつけるイメージです。
また、「UNION」と「UNION ALL」の2種類があり、「UNION」は重複した行を1つにまとめてくれますが、「UNION ALL」は重複した行をそのまま2行表示します。登場頻度は「UNION」のほうが多いような気がします。
特徴としては、SELECTの後に指定する列が同じであること、SELECT文の直後にすぐSELECT文が来ることです。午後問題の穴埋めなどで、穴が2つのSELECT文の間に挟まる場所にある場合は、ほぼ確実にUNIONになります。
INTERSECT
INTERSECTは論理演算で言う「積(AND)」です。
書き方はUNIONと同じで、「UNION」を「INTERSECT」に書き換えるだけです。
2つの表のどちらにも存在する行を抜き出して新しい表を作ってくれます。
EXCEPT
EXCEPTは論理演算で言う「差(NOT)」です。
書き方はUNIONと同じで、「UNION」を「ESCEPT」に書き換えるだけです。
表1ー表2(表1 AND NOT 表2)のイメージで、表1に存在し、かつ表2には存在しない行を抜き出して新しい表を作ってくれます。
CROSS JOIN
CROSS JOINは「直積」と呼ばれます。
SELECT 列名または* FROM 表1 CROSS JOIN 表2
SELECT 列名または* FROM A,B
上記2つのどちらの書き方でも結果は一緒になります。
直積は表1と表2を総当たりで組み合わせるようなイメージです。直積表の列数は両方の列数を足した数となり、行数は両方の行数をかけた数となります。
関連性を全く考えずすべてを組み合わせてしまうので、使いどころには注意が必要です。
データ操作言語の基礎知識② 選択条件の指定(WHERE句)
WHERE句は選択条件の指定ができるゾーンです。SELECT、FROMの後に来ます。
選択条件を指定することで、表の中から特定の行を抜き出すことができます。選択条件を複数指定するときは、条件をANDでつないでいきます。
比較演算子
比較演算子とは、等号や不等号のことです。
例えば、「WHERE 年齢 >= 18」とすれば、年齢という列に入っているデータがが18歳以上の行を取り出すことができます。
ただし、「18 <= 年齢 <=30」という使い方はできません。この場合は、「年齢 >=18 AND 年齢 <= 30」と書く必要があります。
IS NULL
IS NULLを使うと、その列のデータの値が空値(NULL)である行を取り出すことができます。
NULLはデータが入っていないので、そもそも比較ができません。そのため、比較演算子である「=」ではなく、「IS」を使うのです。
例えば、所属部門が決定しておらず、データが何も入っていない社員を抽出する際は、「WHERE 所属部門 IS NULL」と書きます。逆に、データが入っている行を抽出したい場合は「WHERE 所属部門 IS NOT NULL」と記述すれば抽出できます。
BETWEEN
BETWEENは、列の値がここからここまでであれば抽出する、という操作ができます。
「WHERE 年齢 BETWEEN 18 AND 30」と書くと、年齢の列に18以上30以下のデータが入っている行を抽出してくれます。
逆に「WHERE 年齢 NOT BETWEEN 18 AND 30」と書くと、17以下、31以上のデータの行が抽出されることになります。
IN
INは、列の値が( )の中のいずれかである場合は、その行を抽出します。
「WHERE 年齢 IN (20,21,22,23)」と書くと、年齢の列の値が20以上23以下である行が抽出されることになります。
例のごとく、「WHERE 年齢 NOT IN(20,21,22,23)」と書くと、まったく逆の結果が得られます。
LIKE
LIKEは、この文字を含むデータが入っている行を抽出する、という操作ができます。
- % ・・・ 0文字以上を好きに入れられます。
- _ ・・・ 1文字を好きに入れられます。
| 氏 | 名 |
| 田中 | 花子 |
| 佐藤 | 美和子 |
| 佐々木 | 拓郎 |
| 鈴木 | 翔太 |
例えば上記のような表があったとき、
- 「SELECT 名 FROM 名前表 WHERE 名 LIKE %子」 → 「花子」と「美和子」が抽出される。
- 「SELECT 名 FROM 名前表 WHERE 名 LIKE _子」 → 「花子」が抽出される。
という結果になります。なんなら%を使っているほうは名が「子」だけでも抽出してくれます。
データ操作言語の基礎知識③ 集合関数
- SUM(列名)→その列の合計を出力。
- AVG(列名)→その列の平均を出力。
- MAX(列名)→その列の最大値を出力。
- MIN(列名)→その列の最小値を出力。
- COUNT(列名)→列の値がNULLでない列の数を出力。
- COUNT(*)→すべての列数を出力。
データ操作言語の基礎知識④ グループ化
グループ化とは、同じデータが入った行をひとまとめにすることです。「GROUP BY 列名」と記述します。
| クラス | 氏名 | 点数 |
| 1 | 佐藤 美香 | 90 |
| 1 | 佐々木 隼人 | 76 |
| 1 | 高木 優 | 89 |
| 2 | 渡辺 海斗 | 92 |
| 2 | 西田 あかり | 80 |
↓
SELECT クラス, AVG(点数) AS 平均点数, COUNT(*) AS 人数 FROM 点数表 GROUP BY クラス
↓
| クラス | 平均点数 | 人数 |
| 1 | 85 | 3 |
| 2 | 86 | 2 |
こんな感じになります。今回はクラスが同じ行をまとめ、平均点数を出したり人数を数えたりしました。また、上記のSQLのように「AS」を使うことで列名に別名を付けることができます。
注意点としては、クラスでひとまとめにしますので、SELECT句に「氏名」を選択することはできません。「え、何人か分の氏名のデータがあるけど、誰のやつを表示すればいいの?」となってしまうからです。
つまり、SELECT句に指定できるのは、「GROUP BY」で書いた列名、もしくは集合関数のみということです。
データ操作言語の基礎知識⑤ 出力順の指定
指定した列の値をもとに、昇順もしくは降順に並べ替えてくれます。
「GROUP BY」の後に記述し、「ASC」は昇順、「DESC」が降順という形で指定します。
「ORDER BY 年齢 ASC」と書けば、年齢が小さい順にデータを並べ替えてくれるというイメージです。
まとめ
応用情報技術者試験データベース編①はここまでとなります!続きはデータベース編②として別記事に書いていきますので、ぜひそちらもご覧ください!



コメント